
Pizza for dinner, cake for dessert, and leftover pizza for breakfast... sounds like a slumber party!
From left to right: Chad, Haley, Markus, Brady, Kristi
Day 139
It must have been someone’s birthday
August 12th, 2010
Pizza for dinner, cake for dessert, and leftover pizza for breakfast... sounds like a slumber party!
From left to right: Chad, Haley, Markus, Brady, Kristi
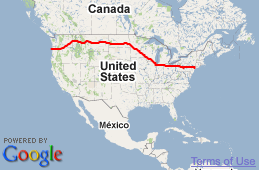
Am I finally first? Another great family on this journey of yours. You’ve probaby made friends for a lifetime.
Congrats finallee…Whoop-Whoop, Karen!
Yay Karen!
Little Haley is like a piece of sunshine. Thanks to Chad and family for Matt’s slumber party :)
What great welcoming food….. yeah for Matt another great family along the way… many thanks to Chad and family!
You can never get too much pizza! How sweet of this family to invite you in!
and My fav, Day after Morning Pizza!!
No Microwave No Oven No Heat
My wife thinks I’m nuts eating it cold.
I think it has the best flavor then.
Matt waves bye to Chad and Kristi,
Brady, Haley and Markus
then walks steadily down the road,
Ain’t no sound but the sound of his feet,
the Runabout’s always ready to go
Are you ready, are you ready for this
Are you hanging on the edge of your seat
Out on the freeway the trucks rip passed
To the sound of his feet
(Yeeaaahh….)
Another mile bites the dust
Another mile bites the dust
(done…done…done)
And another mile gone, and another mile gone
Another mile bites the dust
Hey, I’m headin’ to Walkaway
Another mile bites the dust!
Young! You are just out of control with these songs! LOL I love it… now that will be in my head for the rest of the day…thanks! :D
Awesome!
Amazing young!!
Pizza, breakfast of champions!
Thanks to another fine group of people looking after Matt.
I LOVE leftover pizza for breakfast, when the dough gets a little chewy and the cheese sizzles when you heat it up in the nuke’m. Oh, to be a fly on the wall when you stay with folks along the way.
Thanks Chad and everyone for welcoming Matt into your house. Did he eat like a horse since he stayed in Horse Heaven last night? Just kidding!!! I couldn’t pass that one up. Now he can say he slept in Horse Heaven! Thanks for feeding him dinner and CAKE for dessert. There’s nothing like leftover pizza for breakfast! (and cake too!) I love having cake for breakfast dessert.
MMMMMMMMMMMM. cake and pizza.
Way to go Chad and family!
Thank you, Chad, Kristi and family, for taking care of our boy.
Wow…I am the next house down the road. Sorry I missed it all. Can’t wait to talk to Chad and family to hear all about it.
Diane,
The gate at your place is beautiful. Luckily it was immortalized by Matt.
Awwwww…you missed Matt?? Bummer. Go chase him down he can’t be that far away! But then again, he seems to move fast so maybe he is.
Diane your gate is awesome…. would love to see pics of the horses!
Thanks to Chad and family for taking such good care of Matt! What more does a person need than pizza and cake? Diane, welcome to Hobo Nation! Enjoy!
Cute family. Glad you are finding some people again to stay with instead of da bears!
Thanks Chad and family! I hope you had a great evening with Matt!
This looks like another all AMERICAN family. Markus has a CHAMPION ATHLETICS shirt on but every family member is a CHAMPION.
Again-Matt is loaded with carbs for his trek-PIZZA not just for supper but breakfast-Pizza is breakfast of CHAMPIONS!!!
Thanks to Chad, Haley, Markus, Brady and Kristi!!!
i think chad totally looks like rick harrison from pawn stars. thx 4 takin care of matt!
Birthday party? Sounds like a typical night/morning at my house! Thank you Chad, Kristie, and family for taking care of Our Matt!